Twitter is one of the most influential social media platforms ever to exist. Millions of people including top politicians, celebrities, and CEOs use the platform to share their thoughts every day.
The trending tab is one of the best places to find out real-time news and social media sentiment. You can analyze and use this data to plan brand advertisements, run campaigns, and boost sales by folds. But how can you get the top ten trending hashtags on Twitter?
The Algorithm Building Process
The first step to building any program is to note and understand the steps required to build a Twitter scraper. They are:
- Open Google Chrome.
- Visit Twitter's trending page.
- Gather the hashtags and their respective page link.
- Save the data in a spreadsheet.
This serves as the algorithm of the problem statement.
Understanding the Twitter Webpage
You need to know how a web page marks up its data before you can extract it. It helps a lot if you have a good understanding of the basics of HTML and CSS.
Follow these steps to work out how Twitter represents a trending hashtag and its URL:
- Visit Twitter's trending page. You can also navigate to Twitter.com → Explore → Trending to view it.
- Inspect the main column using Chrome Dev Tools. Go to Menu (3 dots) > More Tools > Developer Tools and hover the element picker tool over the trending area.
-
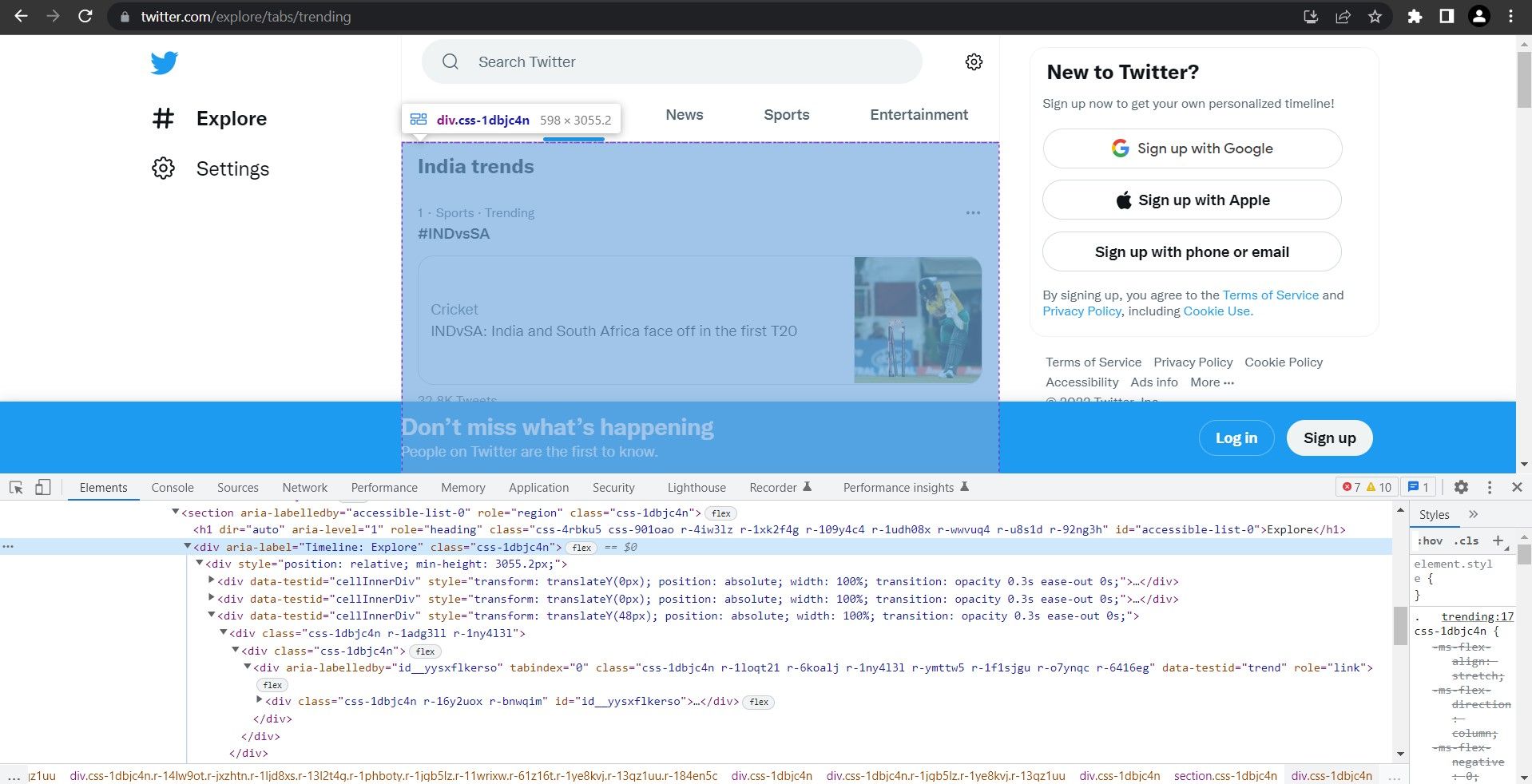
The Trending Timeline is a div with an aria-label attribute whose value is "Timeline: Explore".
Hover over the markup in the Elements panel to better understand the page structure. Another div stores the trending hashtag/topic. Use this div as a counter and iterate to all the divs in the page containing the trending topic/hashtag.
 The content is stored within a span or a couple of span elements.
The content is stored within a span or a couple of span elements.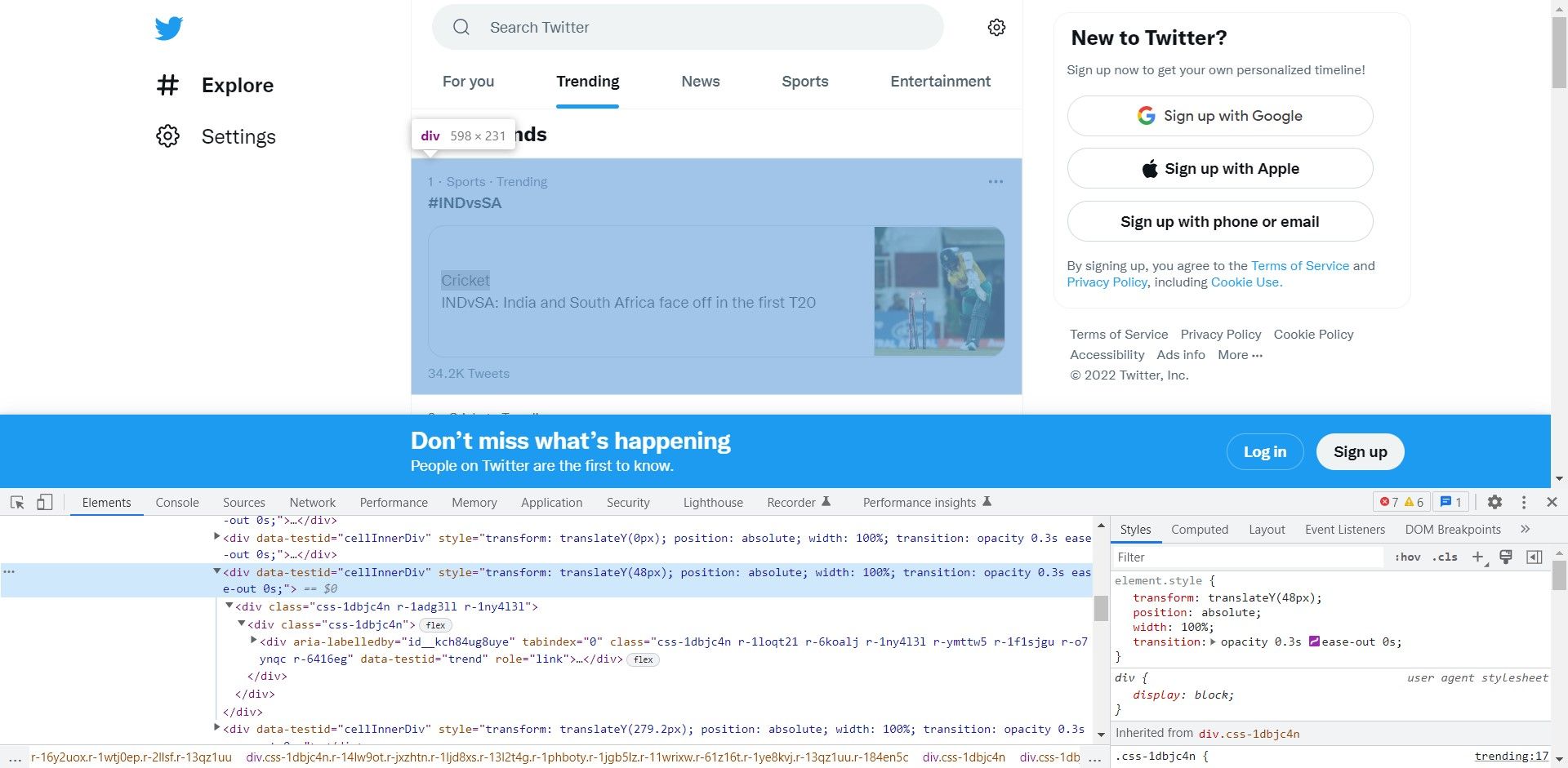 Observe the open tab and note the hierarchy. You can use this to construct an XPath expression.
Observe the open tab and note the hierarchy. You can use this to construct an XPath expression.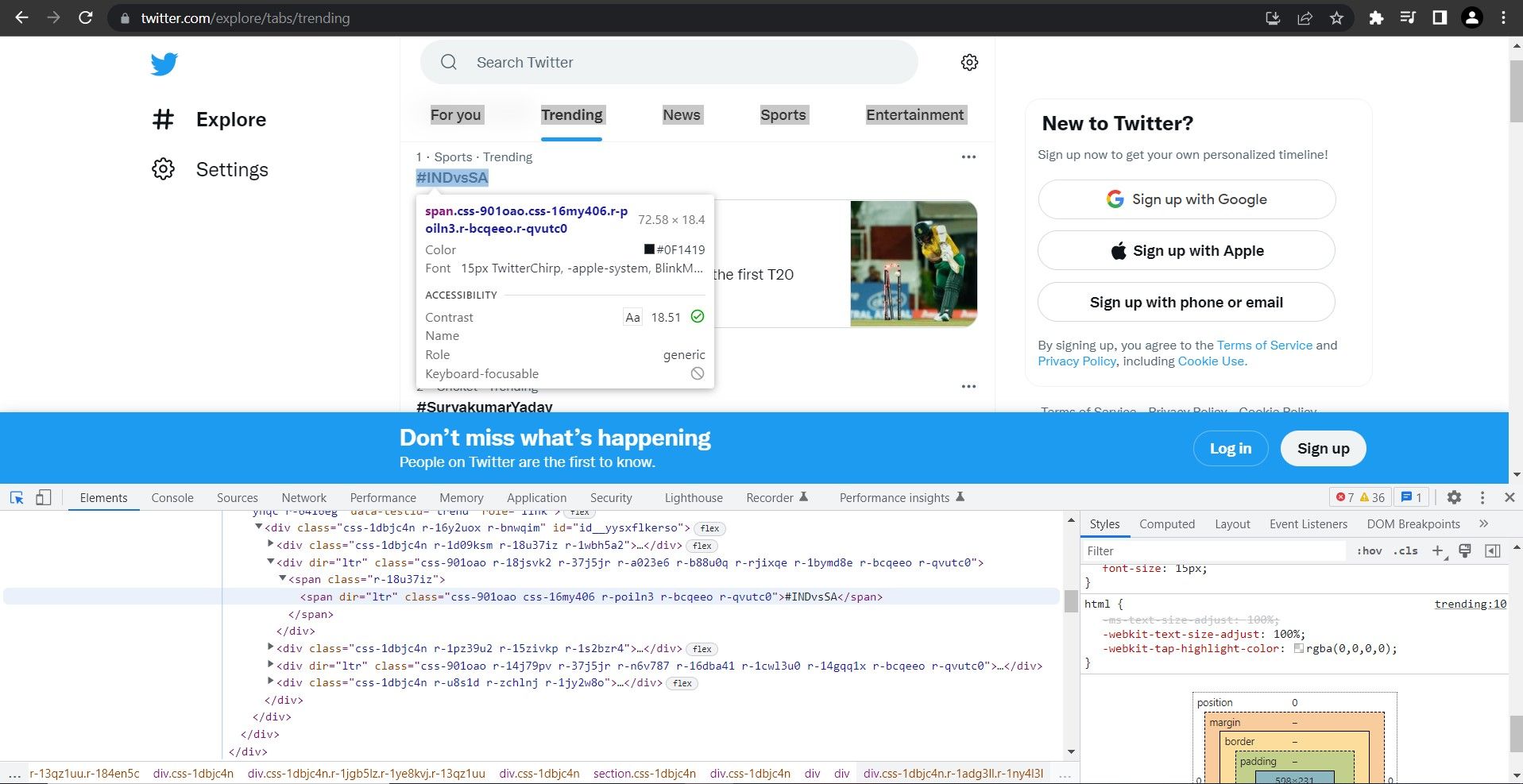 The XPath expression for this specific element is:
The XPath expression for this specific element is: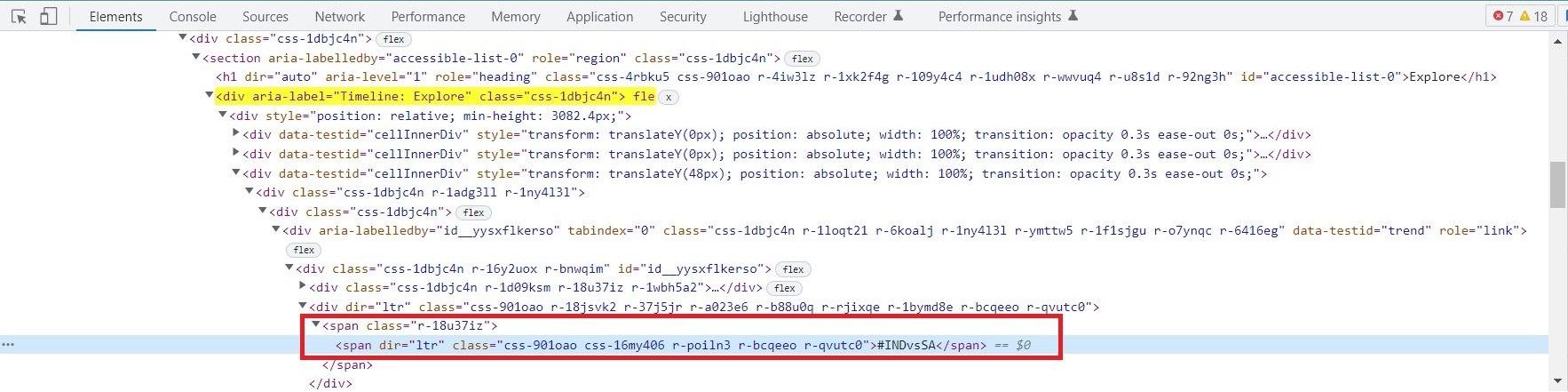
'//div[@aria-label="Timeline: Explore"]/div[1]/div[3]/div[1]/div[1]/div[1]/div[1]/div[2]/span[1]'//div[@aria-label="Timeline: Explore"]/div[1]/div[{i}]/div[1]/div[1]/div[1]/div[1]/div[2]/span[1]' -
Click on any hashtag to understand the URL of its pages. If you compare the URLs, you should notice that only the query parameter changes to match the name of the hashtag. You can use this insight to build URLs without actually extracting them.
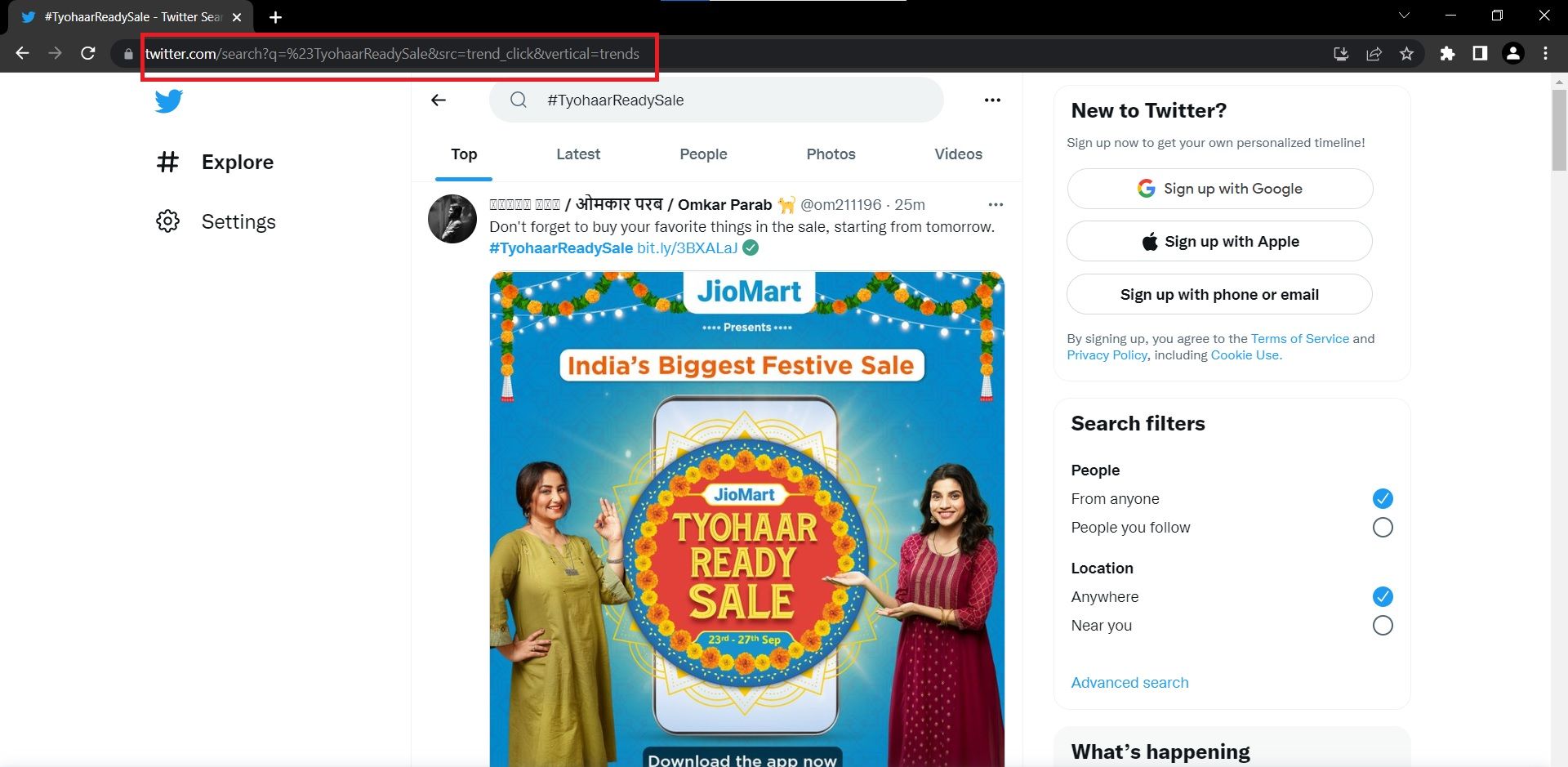





Understanding and Installing the Required Modules and Tools
This project uses the following Python modules and tools:
1. Pandas Module
You can use the Pandas DataFrame class to store the hashtags and their respective links in a tabular format. This will be helpful when it comes to adding these contents to a CSV file that you can share externally.
2. Time Module
Use the Time module to add a delay to the Python program to allow for the page contents to load fully. This example uses a delay of 15 seconds, but you can experiment and choose an appropriate delay for your circumstances.
3. Selenium Module
Selenium can automate the process of interacting with the web. You can use it to control an instance of a web browser, open the trending page, and scroll down it. To install Selenium in your Python environment, open your Terminal and execute pip install selenium.
4. Web Driver
Use a web driver in combination with Selenium to interact with the browser. There are different web drivers available based on the browser you want to automate. For this build, use the popular Google Chrome browser. To install the web driver for Chrome:
-
Check the version of the browser you're using by visiting the Menu (3 dots) > Help > About Google Chrome.
-
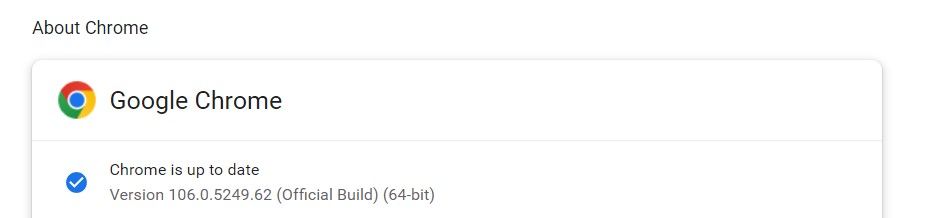
Note the version of the browser; in this case, it's 106.0.5249.62.
-
Go to your Terminal and type pip install chromedriver-binary==version_number:
pip install chromedriver-binary==106.0.5249.62


How to Build the Twitter Scraper
Follow these steps to build your program and get real-time trending hashtags. You can find the complete source code in this GitHub Repository.
-
Import the required modules into the Python environment.
# importing the required modules
from selenium import webdriver
from selenium.webdriver.common.by import By
import chromedriver_binary
import time
import pandas as pd -
Create an object to initialize the ChromeDriver and launch the Google Chrome browser using the webdriver.Chrome() function.
# open google chrome browser
browser = webdriver.Chrome() -
Open Twitter's trending page by passing its URL to the get() function.
# open the trending page of Twitter
browser.get('https://twitter.com/explore/tabs/trending') -
Apply a delay so that the page's contents are loaded fully.
# delay for page content loading
time.sleep(15) -
Create an empty list to store the hashtags and declare a loop that runs from 3 to 13 to match the variable in the XPath expression from before.
# initialize list to store trending topics and hashtags
trending_topic_content=[]
# collect topics and hashtags on Twitter's trending page
for i in range(3,13): -
Use the find_element() function and pass the XPath selector to get the trending topics and hashtags on Twitter:
xpath = f'//div[@aria-label="Timeline: Explore"]/div[1]/div[{i}]/div[1]/div[1]/div[1]/div[1]/div[2]/span[1]'
trending_topic = browser.find_element(By.XPATH, xpath)
trending_topic_content.append(trending_topic.text) -
Create an empty list to store all the URLs and declare a loop that runs through all the hashtags.
# create URLs using the hashtags collected
urls=[]
for i in trending_topic_content:if i.startswith("#"):
i = i[1:]
url='https://twitter.com/search?q=%23' + i + '&src=trend_click'
else:
url = 'https://twitter.com/search?q=' + i + '&src=trend_click'
url = url.replace(" ", "%20")
urls.append(url) -
Create a key-value pair Dictionary with keys as hashtags and values as their URLs.
# create a dictionary that has both the hashtag and the URLs
dic={'HashTag':trending_topic_content,'URL':urls} -
Convert the unstructured dictionary into a tabular DataFrame.
# convert the dictionary to a dataframe in pandas
df=pd.DataFrame(dic)
print(df) -
Save the DataFrame to a CSV file that you can view in Microsoft Excel or process further.
# convert the dataframe into Comma Separated Value format with no serial numbers
df.to_csv("Twitter_HashTags.csv",index=False)
Gain Valuable Insights Using Web Scraping
Web scraping is a powerful method to obtain desired data and analyze it to take decisions. Beautiful Soup is an impressive library that you can install and use to scrape data from any HTML or XML file using Python.
With this, you can scrape the internet to gain real-time news headlines, prices of products, sports scores, stock value, and more.